前三篇文章里,我们从 MCP 配置出发,逐步深入到 Context 优化,再到 Agent 底层架构的原理。这条路走下来,你大概已经能把 Claude Code 跑起来,也知道了它背后在做什么。
但"跑起来"和"用好"之间,还有一段距离。
实际使用中,很多人会遇到一个困惑:配置照着文档做了,Prompt 也写得很仔细,但效果还是时好时坏——同一个任务,今天做得好,明天就跑偏了;代码改了但逻辑没对;或者越到后期,Claude 越像在自说自话。
问题不在于模型能力,而在于系统设计。Claude Code 不是一个对话框,它是一个可以工程化配置的 AI 协作系统。本文聚焦于工程实践层面,帮你把 Claude Code 用得更稳、更可控。
六层架构:系统视角看 Claude Code
在谈具体技巧之前,先建立一个整体视角。Claude Code 的可配置能力可以分为六层:
| 层级 | 组件 | 职责 |
|---|---|---|
| 第一层 | CLAUDE.md | 项目契约:约束行为、定义边界 |
| 第二层 | Tools / MCP | 外部能力:文件、命令、API 访问 |
| 第三层 | Skills | 专业能力:按需加载的领域知识与流程 |
| 第四层 | Hooks | 强制保障:确保关键步骤不被跳过 |
| 第五层 | Subagents | 隔离执行:保护主上下文不被污染 |
| 第六层 | Verifiers | 验证闭环:提供客观的任务完成信号 |

这六层不是独立的——它们构成一个系统。只强化其中一层,系统就会失衡。比如配了很多 MCP 但没有 Verifier,Claude 会做很多事情,但你不知道做对了没有;有了 CLAUDE.md 但没有 Hooks,Claude 可能在压力下(上下文快满时)悄悄跳过约束。
工程实践的本质,就是让这六层各司其职、协同运转。
CLAUDE.md 工程化:项目契约,不是知识库
CLAUDE.md 是 Claude Code 最重要的配置文件,但很多人把它用错了——写成了一份项目文档或知识百科。
正确定位:CLAUDE.md 是"契约",不是"知识库"。 它告诉 Claude 在这个项目里如何行动,而不是了解什么。
应该放什么 vs 不该放什么
| 应该放 ✅ | 不该放 ❌ |
|---|---|
构建命令(npm run build、make test) |
详细的功能介绍 |
| 架构边界(哪些模块不能互相依赖) | 完整的 API 文档 |
安全规则(不能 git push --force main) |
所有的设计决策背景 |
| 代码风格约定(缩进、命名规范) | 以往的 bug 修复记录 |
| Compact Instructions(压缩时保留什么) | 人员分工和联系方式 |
一份高质量的 CLAUDE.md 模板结构:
|
|
几个实用技巧
用 # 快捷追加:在会话中输入 # 这个项目用 pnpm 不用 npm,Claude 会自动将这条规则写入 CLAUDE.md,无需你手动编辑。
HANDOFF.md 接力模式:跨会话切换时,让 Claude 在会话末尾生成一份 HANDOFF.md,记录当前任务进度、未解决的问题和下一步建议。新会话开始时直接引用这个文件,避免从头解释上下文。
让 Claude 维护 CLAUDE.md:在 CLAUDE.md 里写一条规则:“如果你在执行过程中发现了应该记录的项目约定,主动更新 CLAUDE.md”。这样随着项目推进,规则会自动沉淀。
验证闭环:给 Claude 自我检验的能力
官方文档里有一句话我认为是整个工程实践的核心:
给 Claude 提供自动化验证工具,可能是单一最高杠杆的操作。
没有 Verifier,就没有工程意义上的 Agent。Claude 在没有外部反馈的情况下,很容易陷入"自我感觉良好"的状态——代码写完了,但测试没跑;功能实现了,但 lint 报错了。
验证闭环分三个层级:
| 层级 | 验证方式 | 实现成本 | 适用场景 |
|---|---|---|---|
| 基础层 | 命令退出码、lint、单元测试 | 低 | 代码修改类任务 |
| 中间层 | 集成测试、截图对比、E2E 测试 | 中 | 前端、API 开发 |
| 顶层 | 生产日志、人工审查 | 高 | 高风险变更 |
Before / After 对比:
|
|
在 CLAUDE.md 里定义验收标准是最省力的方式:
|
|
Plan Mode:探索与执行分离
Plan Mode 解决的问题是:避免在错误假设上越跑越偏。
没有 Plan Mode 时,Claude 可能在对需求理解不足的情况下就开始动文件,越改越乱,最后你不得不 git checkout . 全部回滚。
Plan Mode 强制将任务拆分为两个阶段:
第一阶段(探索):Claude 只读取文件、理解现有代码,不做任何修改。
第二阶段(执行):方案经过你确认后,Claude 再开始实际修改。
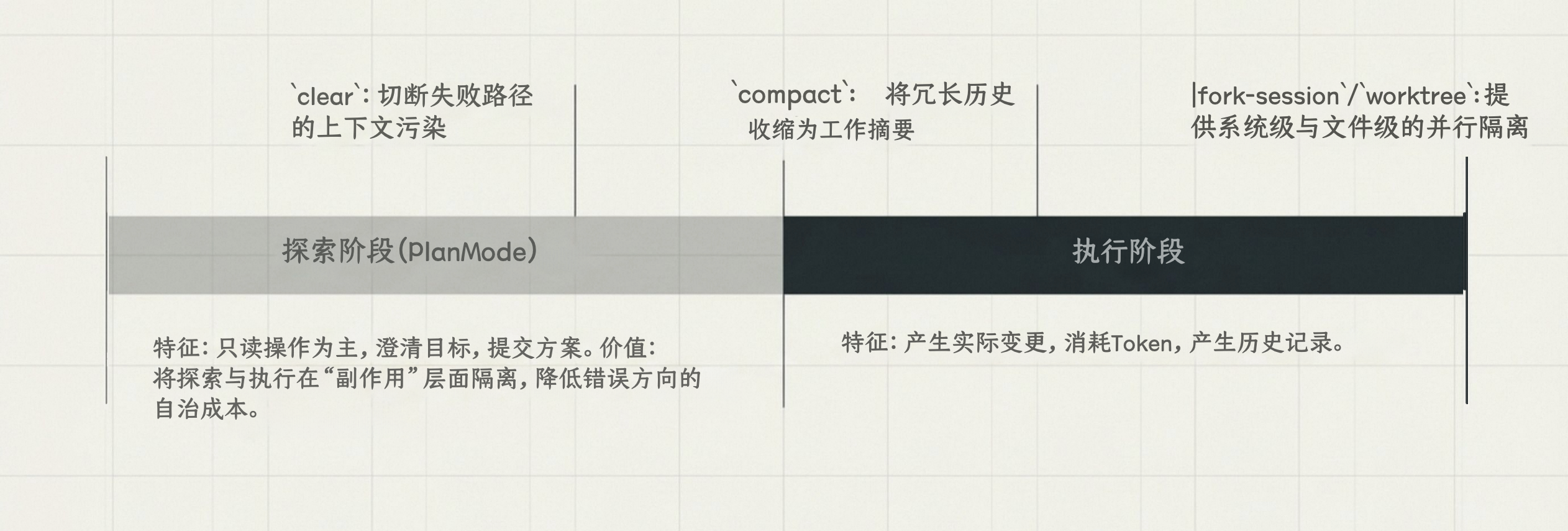
四步工作流
- Explore:
/plan进入 Plan Mode,让 Claude 阅读相关文件,理解现状 - Plan:Claude 产出实现方案,包括要改哪些文件、改什么逻辑
- Review:你审查方案,确认没有误解或遗漏
- Implement:
/exit-plan或直接批准,Claude 开始执行
进阶玩法:用一个 Claude 实例写出计划,再启动第二个 Claude 实例,以"高级工程师"的身份审查这份计划,找出潜在问题。两个实例互相博弈,比单独一个实例更可靠。
什么时候不需要 Plan Mode:任务目标完全明确、只涉及单个文件的小改动、或者你对结果有充分把握时,不必强行走 Plan Mode,直接执行更高效。
Skills 设计模式:三种典型类型
Skills 不只是"功能说明书",设计好的 Skill 可以显著提升任务质量和一致性。
类型一:检查清单型
适合:质量门禁、发布流程等需要逐项确认的场景。
|
|
类型二:工作流型
适合:标准化的多步骤操作。可以配合 disable-model-invocation: true,让整个 Skill 成为纯脚本执行流,不额外消耗 LLM 调用。
|
|
类型三:领域专家型
适合:封装复杂的决策框架,让 Claude 在特定领域的表现更专业。
|
|
描述符优化
Skill 的描述字段影响 Claude 是否会自动调用它,也会常驻在 context 中消耗 token。短描述节省 context,但触发精准度下降;长描述更精准,但占用更多空间。
一个原则:描述符说"什么时候用",正文才说"怎么用"。
|
|
如果某个 Skill 很少用(比如年度审计流程),加上 disable-auto-invoke: true,避免 Claude 误触发。
Hooks:把不能交给 Claude 临场发挥的事收回来
CLAUDE.md 是"建议",Claude 可以遵守,也可能在上下文压力大时悄悄跳过。Hooks 是"强制",无论 Claude 打算做什么,Hooks 都会执行。
适合 vs 不适合放 Hooks
| 适合放 Hooks ✅ | 不适合放 Hooks ❌ |
|---|---|
| 每次保存文件后自动 lint | 需要 LLM 判断的逻辑 |
| 写入特定目录前发出警告 | 复杂的业务流程 |
| 任务完成后发送桌面通知 | 需要上下文理解的检查 |
| 防止修改受保护的文件 | 性能敏感的路径 |
实用示例
PostToolUse 自动 lint(每次写文件后自动检查):
|
|
注意末尾的 | head -30——Hook 的输出会进入 Claude 的上下文,截断可以防止输出过长污染后续对话。
文件保护(阻止修改关键配置):
|
|
CLAUDE.md + Skill + Hook 三层叠加
这三者是互补的:
- CLAUDE.md:定义"应该"做什么(软约束)
- Skill:定义"如何"做(专业流程)
- Hook:确保关键操作"一定"被执行(硬保障)
三层叠加,才能覆盖"Claude 理解不到位"、“Claude 忘记执行”、“Claude 跳过步骤"这三类失控场景。
Subagents:隔离,而不只是并行
Subagents 的核心价值不是"并行加速”,而是隔离探索任务,保护主线程上下文。
每个 Subagent 拥有独立的上下文窗口。当你让主 Claude 去探索一个未知的大型代码库,或者尝试一个可能失败的技术方案时,这个探索过程中产生的大量中间状态(读取的文件、遇到的错误、被推翻的假设)不会污染主线程的上下文。

配置时的显式约束
|
|
三个反模式:
- 权限和主线程一样宽:Subagent 的工具权限应该根据任务最小化,探索任务不应有写权限
- 输出格式不固定:主线程需要解析 Subagent 的输出,应该约定结构化格式(JSON 或固定的 Markdown 结构)
- 子任务强依赖:Subagent 之间有强顺序依赖时,隔离带来的好处会大打折扣
会话管理:主动控制上下文
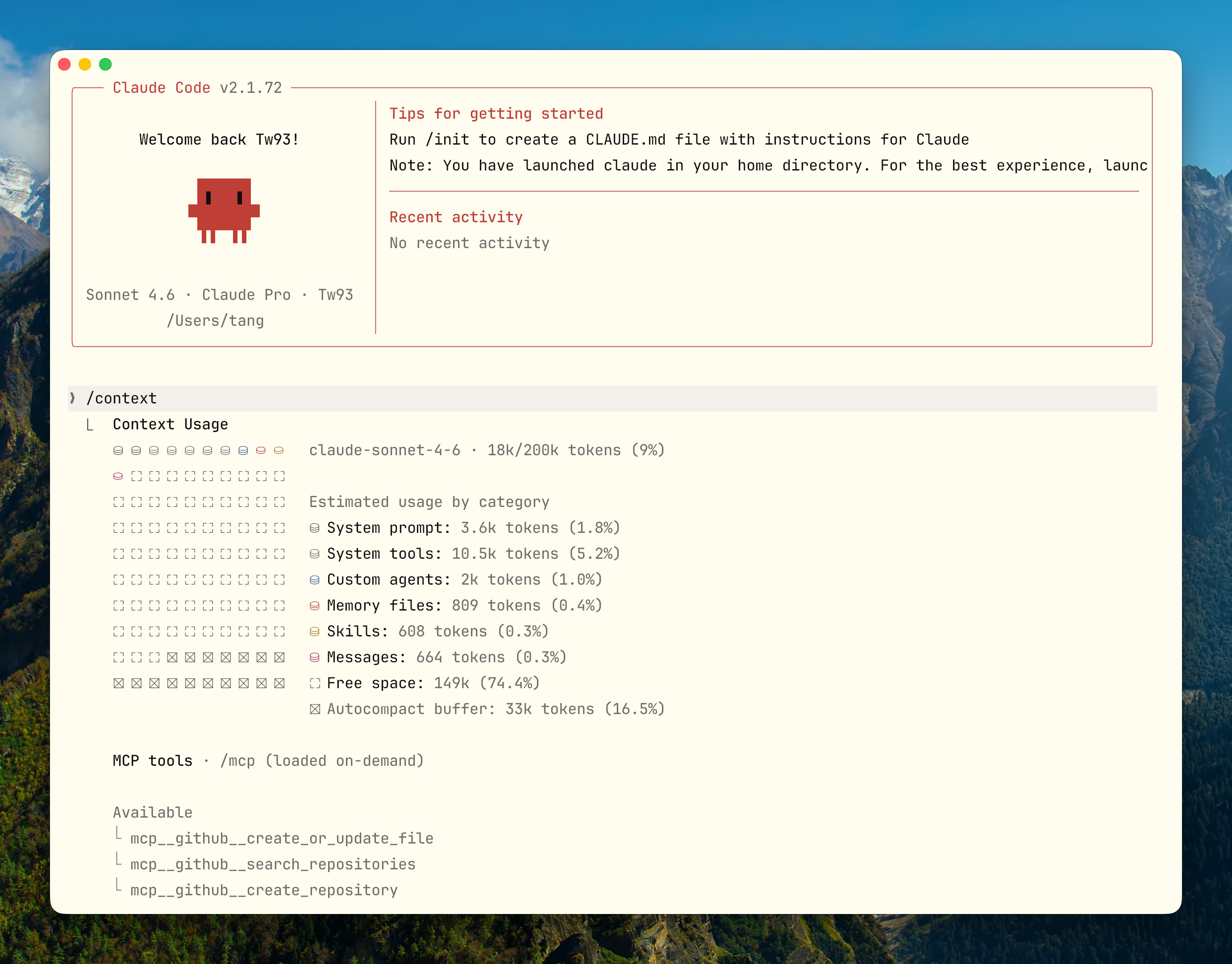
不要等上下文自动溢出,要主动管理它。以下是我最常用的命令:
| 命令 | 用途 |
|---|---|
/context |
查看当前上下文使用量 |
/compact |
手动触发上下文压缩(保留重要信息) |
/clear |
清空上下文,从头开始 |
/memory |
查看和管理持久化记忆 |
/mcp |
检查 MCP 服务器连接状态 |
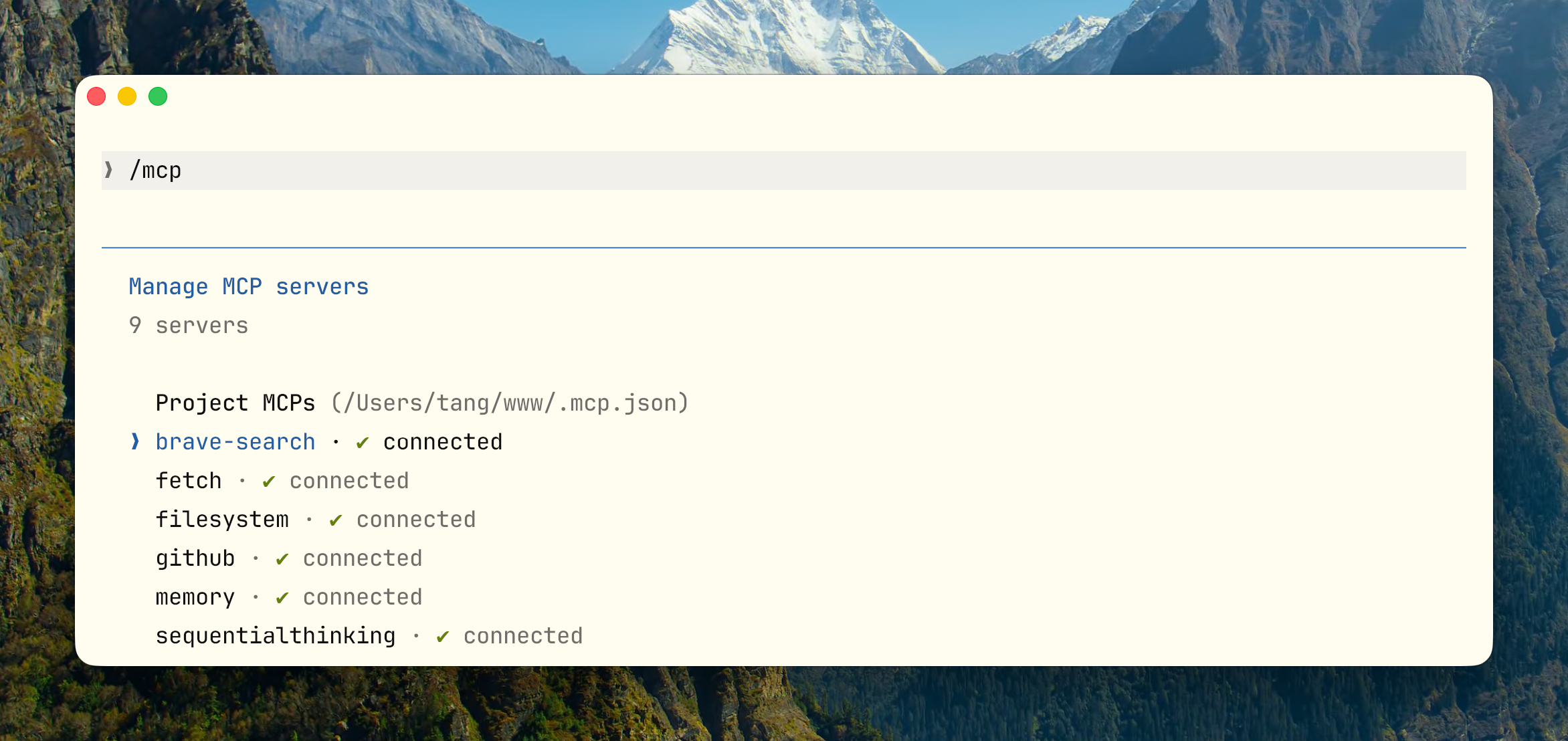
几个不常见但好用的命令:
/btw:旁路问答。在不影响主任务上下文的情况下,临时问 Claude 一个问题/rewind:回溯到上一个状态,撤销最近一次操作(文件修改也会回滚)/insight:让 Claude 分析当前会话,建议更新 CLAUDE.md 的内容
会话恢复与分叉:
|
|
一个实用原则:当你发现自己在会话里反复纠正同一个问题时,不要继续纠正,直接 /clear 重开。反复纠正不会让 Claude 学会,只会让上下文越来越混乱。
常见反模式总结
| 反模式 | 症状 | 修复 |
|---|---|---|
| CLAUDE.md 当 wiki | 文件越来越长,Claude 越来越不遵守 | 删掉知识,只保留约束和命令 |
| Skill 大杂烩 | 一个 Skill 覆盖 5 件不相关的事 | 拆分为职责单一的 Skill |
| MCP 过多 | 响应变慢,context 被占满,前三篇文章有详述 | 迁移到 CLI 工具或 Skill |
| 没有验证闭环 | Claude 说"完成了"但结果不对 | 在任务里显式定义验收标准 |
| 上下文不切分 | 越到后期,Claude 越容易出错 | 用 /compact 或 /clear 主动管理 |
| “厨房水槽"会话 | 把多个不相关任务堆在一个会话里 | 每个任务独立会话,或用 Subagent 隔离 |
| 反复纠正不重开 | 上下文里充斥着纠错历史,模型混乱 | 遇到方向性问题直接重开会话 |
总结:三个阶段
Tw93 在他的文章里提到了 Claude Code 用户的三个阶段,我深有同感:
- 工具使用者:会配 MCP,会写 Prompt,能跑起来就行
- 流程优化者:会设计验证闭环,会用 Plan Mode,开始管理上下文
- 系统设计者:把 CLAUDE.md、Skills、Hooks、Subagents 当成系统组件来设计,而不是单独的功能
大多数人卡在第一阶段,原因通常是没有意识到 Claude Code 是一个可以工程化的系统。
最后一个核心原则值得反复强调:说不清楚"什么叫做完"的任务,不适合直接扔给 Claude 自动完成。 在给出任务之前,先想清楚验收标准,这是让 AI 协作稳定运行的基础。
参考来源: