OpenAI 联合创始人 Andrej Karpathy 前阵子感叹:从 2025 年 12 月开始,软件开发发生了根本性变化。编程从“写代码”变成了“编排 Agent”。 AI 已经能够自己建环境、查 Log、修 bug,全方位实现自主编程。
这种变化正在真实发生。OpenAI 应用 CTO 和 Codex 工程负责人在一次访谈中表示:OpenAI 内部工程师的真实状态,交代完任务,合上电脑去开会,后台服务器会自动并行处理完毕。支付巨头 Stripe 的内部程序 Minions,更是每周全自动提交上千个代码修改。
这已不再是大厂专属。借助爆火的开源项目 OpenClaw,只需建一个普通文本文档(Markdown),写清“任务”和“可用工具”,一个全自动执行任务的程序就能跑起来。
这意味着,交互的本质已经改变:从“一问答”的指令执行,变成了“目标导向”的任务交付。
如果你还在对话框里等 AI 回复一段文本,再手动复制去执行,那你已经落后了。现在的模式是:你只管给出目标,程序自己拆解步骤、调用软件、检查质量并交付成品。这种能自主循环、自动完成任务的软件架构,就是 Agent。
今天我们不谈玄幻概念,只用最直白的语言,一层层拆解 Agent 在底层到底是如何运作的。
大模型到底在干什么?
要弄懂 Agent,必须先了解大语言模型(LLM)。
大模型的本质只有一个:根据概率预测下一个 Token(字符)。
它没有意识,也没有主动思考能力,最底层的功能仅仅是“文本补全”。程序给它发送一段文本(Prompt),它计算出接下来哪个字出现的概率最高,就输出哪个字。比如输入“床前明月”,它预测下一个字是“光”。这就是大模型的全部逻辑。
我们看到的“聊天机器人”,只是对“文本补全”做了一层格式包装。
理解了这一点,一个问题就浮现了出来:如果大模型只会“接收文本、输出文本”,那它是如何去联网查天气、修改文件、执行代码的?
为了解决这个问题,工程师们设计了大模型连接到外部世界的核心机制:Function Calling(函数调用)。
大模型连接外部世界:Function Calling
大模型本身无法执行任何代码。所谓“模型调用了工具”,本质上是一种巧妙的文本格式约定。
Function Calling 的核心是:要求大模型输出一段特定格式的代码文本(通常是 JSON 格式),然后由你电脑上的本地程序去拦截并执行这段代码。
在这个机制下,我们在给模型发送用户问题时,会同时附带一份“工具说明书”(用纯文本写明:你现在拥有一个查天气的函数,需要输入城市名称)。
一旦模型通过概率计算,判断当前的任务需要用到这个工具,它就不会再输出普通的自然语言回复,而是输出一段结构化的数据文本。
让我们通过一个真实的数据流向,来看看“大模型连接外部世界”到底是怎么完成的:
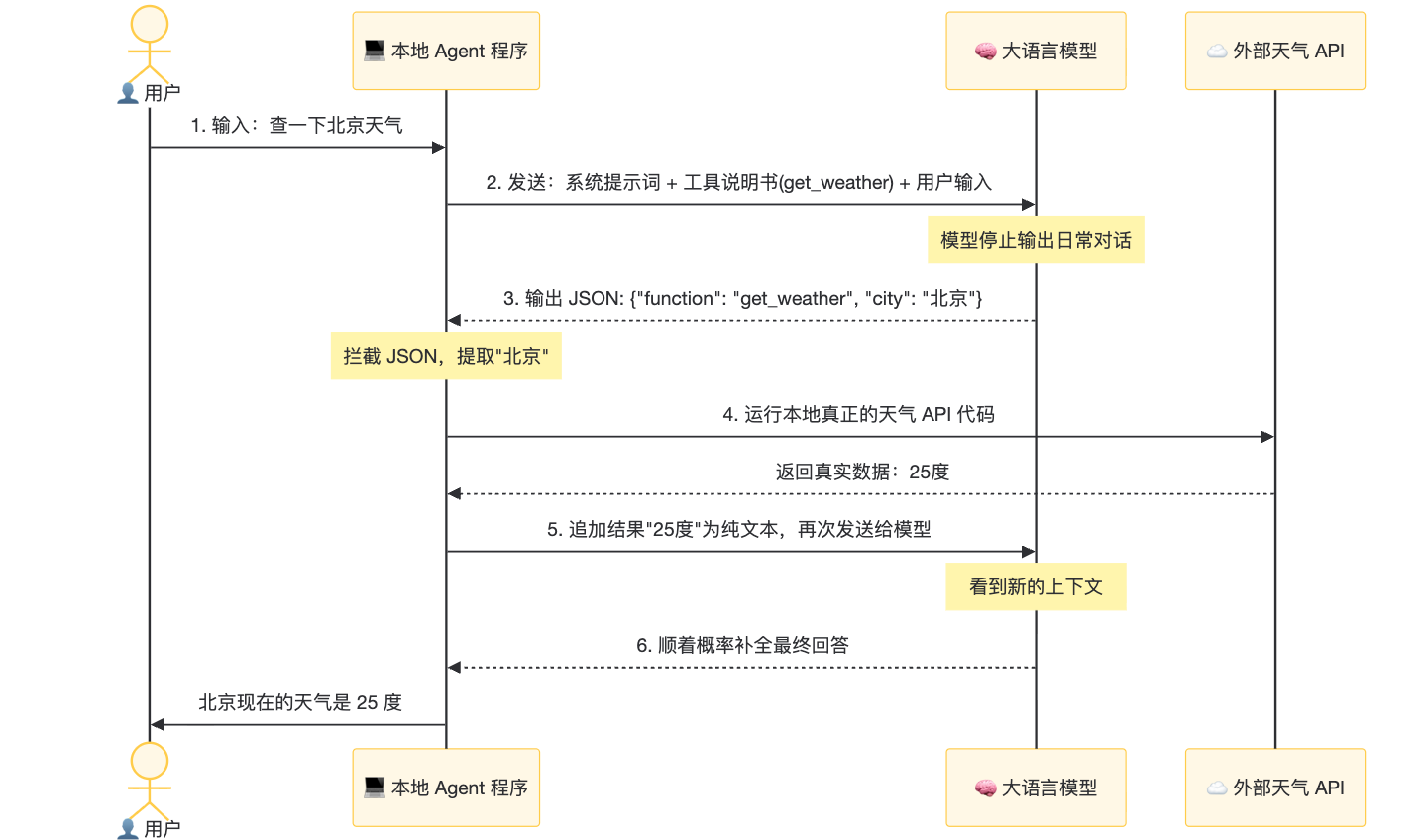
看明白了吗?大模型从来没有真正触碰过外部网络。它只是写了一张格式严谨的“派工单”(JSON 文本),真正的执行者,永远是外部的传统程序代码。这就是大模型走向外部世界的基础。
MCP 让 Agent 连上外面的世界
Function Calling 解决了“如何让模型触发操作”的底层逻辑,但在实际工程中,它带来了一个巨大的痛点。
如果你想让 Agent 读取 GitHub 的代码、查阅 Notion 的文档、操作本地的数据库,按照传统方式,程序员必须为这 3 个完全不同的软件,分别编写 3 套复杂的对接代码。这不仅繁琐,而且难以扩展。
为了消除这种重复开发,行业推出了标准化的交互协议:MCP(模型上下文协议)。MCP 的核心目的,就是让 Agent 真正无缝地连上外面的世界。
MCP 的本质是一套标准化的数据交换格式。所有的外部软件(数据库、企业文档、云服务)只要按照统一的规范提供接口,Agent 就可以直接调取它们的数据。
MCP 意义在于实现了工具的“即插即用”。
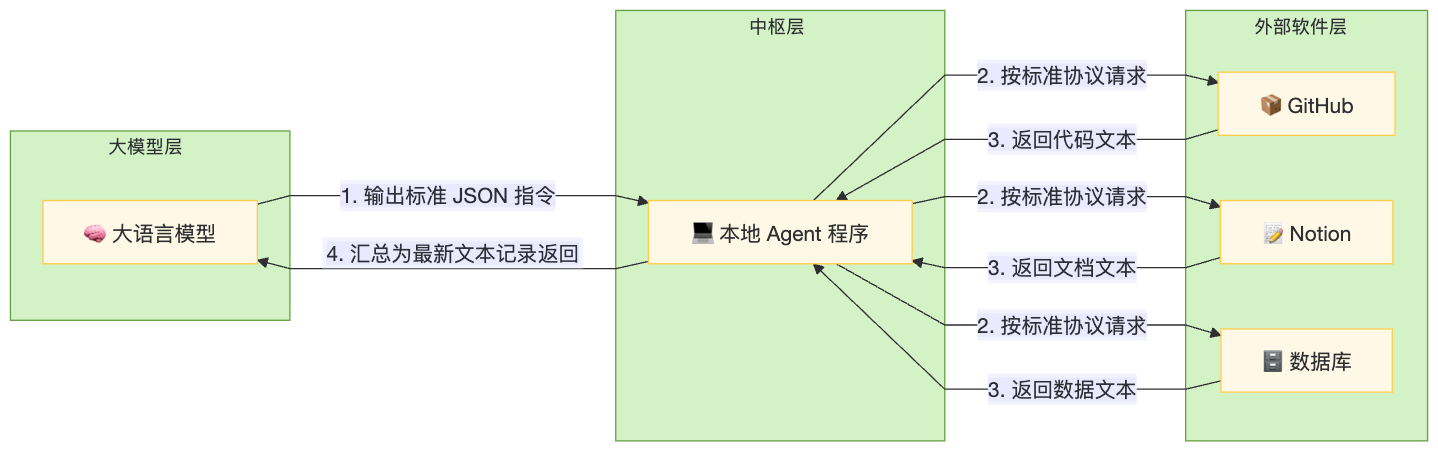
有了 MCP,散落在外部世界的数据和功能,都可以被统一转换为标准文本,直接灌入 Agent 的上下文中。
然而,连上外面的世界仅仅是拥有了操作能力。Agent 要完成如“前端开发”或“财务审计”这样复杂的专业任务,还需要专业的业务知识和操作流程。这就需要用到另一个核心工程机制:Skills(技能)。
Skills:可共享的能力模块,按需加载
如果把所有领域的专业规范和工具,在程序启动时全部发给大模型,会导致输入的文本量过大,,甚至超出上下文限制。
为了解决这个问题,工程师引入了 Skills 机制。
Skills 的本质是可以共享的技能包。它们是预先定义好的能力模块,供 Agent 按需加载。 开发者将特定领域的专业规范、执行步骤预先写在一个独立的文本文件(如 SKILL.md)中。
它的运行机制非常高效:
- 初始状态下,程序只告诉模型它拥有一个
load_skill(加载技能)的基础工具。 - 当模型判断出当前任务是“数据分析”时,它输出 JSON 指令按需加载“数据分析”技能包。
- 本地程序去读取该文件,将其包含的分析规范和代码示例全部追加到当前上下文中。
- 模型获得了专业的指令集,随即开始精准执行任务。

MCP 与 Skills 的竞合关系
在 Agent 架构中,MCP 和 Skills 解决的是同一类问题:如何整合多个系统来完成复杂任务。但它们采用了不同的工程路线,构成了明确的竞争与合作关系。
- MCP 侧重“接口协议化”:它需要部署专门的服务器程序,把模型指令翻译成外部系统的 API 请求。这种方式高度结构化,但开发成本高。
- Skills 侧重“流程文本化”:它极度轻量,直接在文本中写明规范,让模型自己生成命令行脚本(如 bash 执行代码)去请求外部系统。它将业务流转的逻辑交给了大模型自身的代码生成能力。
如果 MCP 服务器已经在代码里写死了所有复杂的业务流程,那么就不再需要 Skills 去指导模型;反之,如果你给 Agent 配置了详尽的 Skills 技能包,让模型自己写脚本去完成系统调度,那么厚重的 MCP 协议层就变得多余。
在最理想的架构中,两者是合作的:MCP 让 Agent 连上外面的世界(提供底层数据和基础功能),而 Skills 为 Agent 按需加载业务能力(指导它如何使用这些数据和功能去完成具体任务)。
Agent 的运行机制:循环与状态的结合
既然大模型只会文本预测,工具调用全靠 JSON 转换,那么 Agent 所谓的“自主完成任务”,到底是怎么实现的?
用一个最简练的公式来总结:Agent = 模型 + 工具 + 循环 + 状态。
Agent 的核心正是“循环 + 状态”。我们可以将它的运转逻辑拆解为以下部分:
- 模型(理解与决策):负责阅读当前状态,理解复杂局面并预测下一步。
- 工具(外部交互):将模型的预测指令转化为真实的系统操作。
- 循环(规划 → 执行 → 观察 → 修正):外层包裹的控制流代码,它赋予了 Agent 持续推进任务和动态纠错的生命力。
- 状态(记忆、进度、上下文):完整保存所有的历史记录与真实反馈,确保模型在循环中始终不偏离最终目标。
在代码层面,Agent 就是一个不断运转的死循环,不断重复以下四个步骤:
- 读取状态:程序将用户的原始输入,以及过去累积的所有操作记录(即任务进度和上下文记忆),发送给模型。
- 规划与决策(模型):模型基于最新的全局状态,推断下一步该做什么(规划),输出相应的 JSON 工具指令。
- 执行操作(工具):本地程序拦截 JSON,运行真正的外部工具(执行),并获取真实结果。
- 观察与修正(循环):本地程序将执行结果转换为纯文本,追加到历史状态中。然后重头开始新一轮推断(一旦报错,模型便能基于新状态进行修正)。
这个循环何时终止?只有当模型判断任务已经彻底完成,不再输出 JSON 工具指令,而是输出代表最终结果的普通自然语言文本时,Agent 才会触发 break 跳出循环,达成最终目标。
为了让你更直观地理解 Agent,我们可以对比一下传统编程、工作流与 Agent 在执行路径上的根本差异:
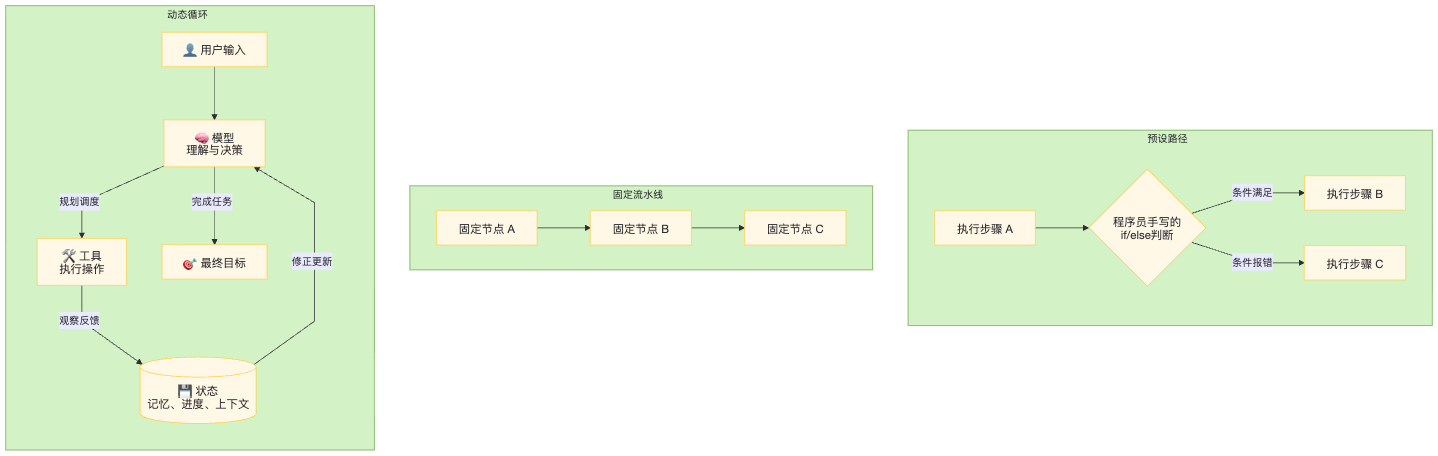
传统编程,程序员必须提前预测所有可能发生的情况,硬编码写死所有的 if/else 逻辑。遇到没写过的新错误,程序直接崩溃。
工作流 (Workflow),由人工预先在界面上连线,规定好“A 节点执行完必须执行 B 节点”。路径是单向且固定的。
Agent 架构,执行路径是在运行中动态生成的。程序本身没有写任何业务逻辑,它只负责传递状态和执行工具。下一步该干什么、遇到报错该怎么修正,全部由大模型基于不断累积的“状态”,在“循环”中实时推断并自主决定。
大模型负责理解与决策,工具负责执行操作,状态负责记录记忆与进度,而正是 “规划 → 执行 → 观察 → 修正” 的这个循环机制将它们完美粘合,诞生了真正的智能体。
不到 20 行代码,看清 Agent 是如何跑起来的
前面讲了这么多概念,在实际写代码时,Agent 到底长什么样?
我们用行业标准的 LangChain 框架,编写一个真实的 Agent 程序。任务是:“买 3 台基础款 iPhone,先查价格,然后算总价,最后下单”。
核心代码:模型、工具与循环的组装
我们略去外部工具内部的具体逻辑代码,只看最核心的 Agent 构建部分。你只需要几行代码,就能把前文所说的机制完全跑起来:
|
|
运行日志与原理解读
当我们运行这段代码,程序并没有像传统代码那样直接出结果,而是通过底层的循环,自动跑了 5 轮。
我们用一张交互图,将这段真实生成的后台日志翻译出来:

回顾这 5 轮真实的交互过程,我们可以清晰地看到 Agent 是如何一步步推进任务的。
代码中并没有设定“先查价、再计算、最后下单”的固定流程。第一轮搜索由于条件过于苛刻导致失败,但程序并没有因此报错退出。相反,失败的反馈信息被原封不动地记入了上下文状态中(观察)。模型在第二轮读取到这段“失败记忆”后,自动调整了搜索参数(修正),成功获取了价格。
拿到单价后,模型结合“买 3 台”的初始目标,在第三轮顺理成章地推断出需要执行乘法计算(规划与执行)。直到第四轮所有前置条件(商品、数量、总价)全部集齐,它才最终下达了创建订单的指令。
这就是 Agent 架构的魅力所在。它跳出了传统代码的线性执行逻辑,通过“模型推断 -> 工具反馈 -> 状态累积”的持续循环,实现了在不确定环境下的动态决策和自我纠错。
Claude Code 底层也是这样吗?
前面我们用不到 20 行代码跑通了一个玩具级的 Agent。其实目前最流行的 Agent 编程工具Claude Code,它的底层也是这种逻辑。
Claude Code 从诞生以来,尽管经历了多次重磅迭代,加入了诸如 Sub-agents(子代理)等复杂特性,但它的核心架构,完全符合我们今天拆解的所有概念:
- Agentic Loop(核心循环):Claude Code 的运转核心就是一个“循环”。程序在“收集上下文(读状态) → 采取行动(调工具) → 验证结果(观察反馈)”这三个阶段中不断打转,逻辑和我们上面的 5 轮推演如出一辙。
- MCP(连接本地与外部):它为什么能自动读取你的本地代码、跑测试脚本甚至操作 GitHub?因为它底层集成了一套完整的 MCP 客户端,将你电脑终端里的所有指令,变成了模型随时可调用的标准工具。
- Skills(按需加载技能):当面对极其复杂的商业项目时,它并不会把几万行的项目规范全部塞进模型的上下文里。它利用 Skills 机制,仅仅在需要时才真正加载专业指令。
结语
在没有理清底层机制之前,很多人对 Agent 的理解停留在表面:以为它是更聪明的对话机器人。
现在你了解了,Agent 的本质,就是将大模型的文本预测能力,放置在一个自动化循环的程序框架内,并赋予其读写外部世界数据的权限。
忘掉传统的“一问一答”模式。从现在开始,尝试在工作中明确你的终点目标,梳理好你手头的数字工具,把它们一起交给你的 Agent 程序,让它进入循环,自主为你交付最终的成品。
欢迎来到 Agent 世界。