今年我有幸参加了开源之夏 (Summer OSPP) 活动,并成功中选了 面向 openEuler distroless 镜像的 SDF 自动生成工具开发 项目。
就在几天前,我收到了 Gitee 的合并通知。那一刻,我感觉自己几个月来的努力都有了最好的回报。经过一段时间的开发、学习和与华为老师的深入交流,我提交的 两 四个 PR 终于先后被合并了!这不仅仅是代码的合入,对我而言意义重大,毕竟这不再是个人玩具项目,而是为华为 openEuler 生态的基础软件贡献代码。我想借此机会,分享一下这段令人兴奋的旅程。
开源之夏 是中国科学院软件研究所发起的“开源软件供应链点亮计划”系列活动,由中国科学院软件研究所与华为共同主办、中科南京软件技术研究院承办。开源之夏为学生提供了接触和贡献高质量开源项目的机会,通过真实的开源项目实践,培养和发掘优秀的开发者,促进优秀开源软件社区的蓬勃发展,助力开源软件供应链建设。开源之夏于 2020 年正式发起,今年已经是第六届,该活动已成为国内开源社区中极具影响力的人才培养平台。

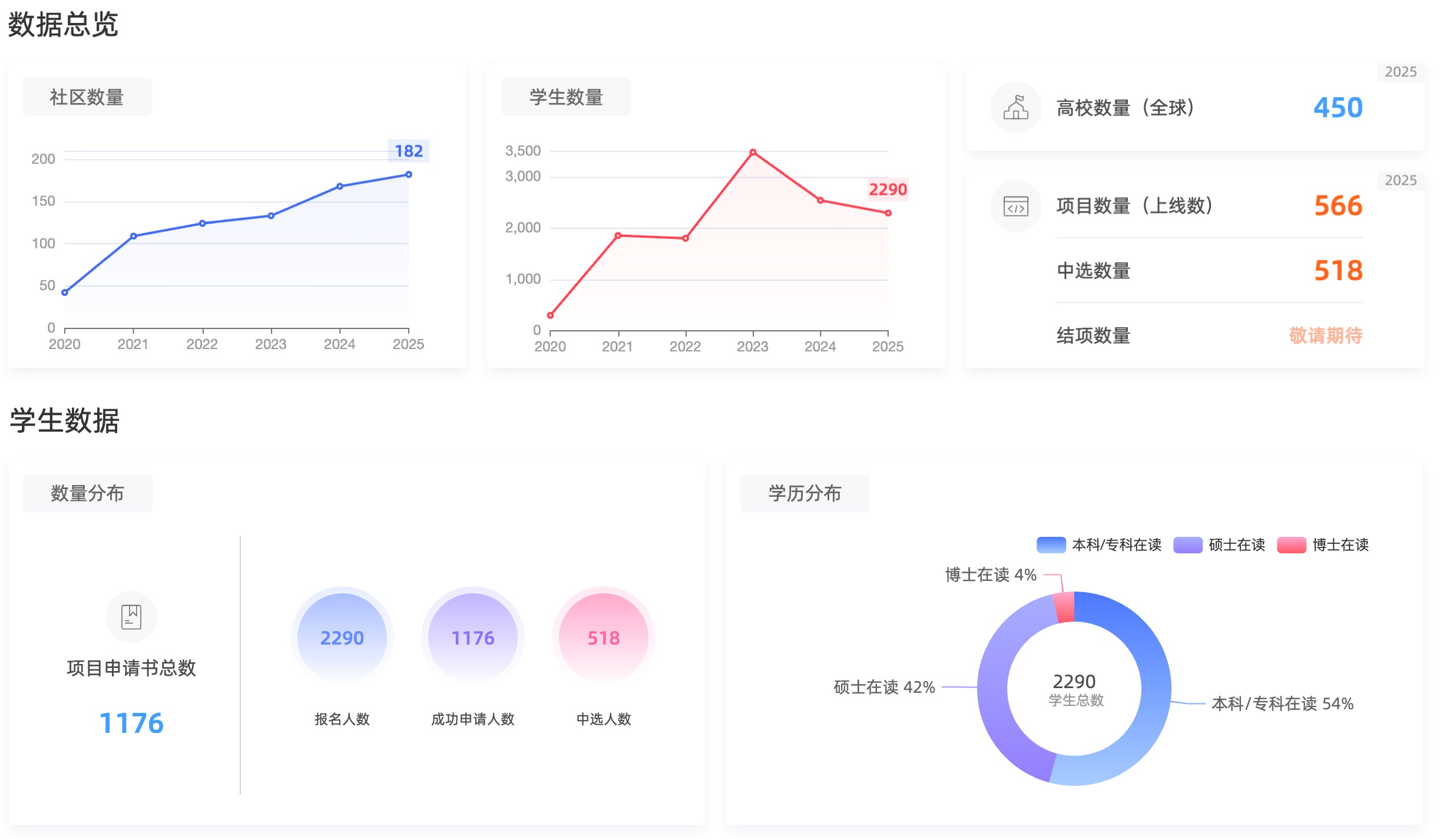
2025 年的开源之夏联合了全球 182 个开源社区,共发布了 566 个项目任务,覆盖了操作系统、人工智能、数据库、云原生、RISC-V 等多个前沿技术领域,吸引了全球 450 所高校,两千多名学生的报名,提交了项目申请书 1176 份,最终 518 名学生中选。
我的任务:为 splitter 打造 SDF 自动生成器
首先简单介绍一下我参与的项目 splitter。
在容器化的世界里,我们追求更小、更安全的镜像。openEuler 的 Distroless 镜像就是为此而生。它的核心思想是,不再完整地打包一个 RPM 软件包,而是将其精细地“切分”成多个功能独立的“Slice”,软件包之间的依赖关系也就更精细地表现为 slice 之间的依赖。然后我们以 slice 为最小构建单元生成最终的 distroless 镜像,可以有效减少冗余文件,进而降低安全风险。
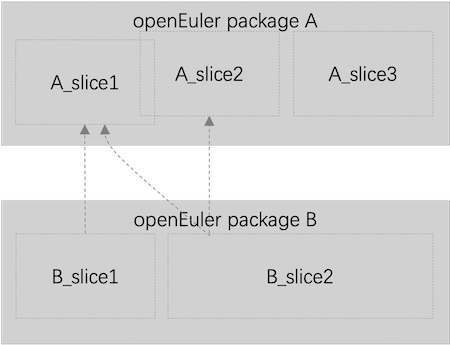
如上图所示,软件包 B 依赖于软件包 A 等价于 B_slice1 和 B_slice2 依赖于 A_slice1、A_slice2,在生成 B 的应用镜像时,可以不再打包 A_slice3 所包含的文件。
splitter 通过解析 RPM 软件包,并根据预定义的规则文件 SDF (Slice Definition File),将软件包切分成多个 slice。
SDF (Slice Definition File) 精准定义每个软件包的拆分规则。目前,所有的 SDF 文件都由社区专家手工编写,存放在 slice-releases 仓库中。当软件包数量和版本不断增多时,手工编写 SDF 就成了一个巨大的瓶颈。
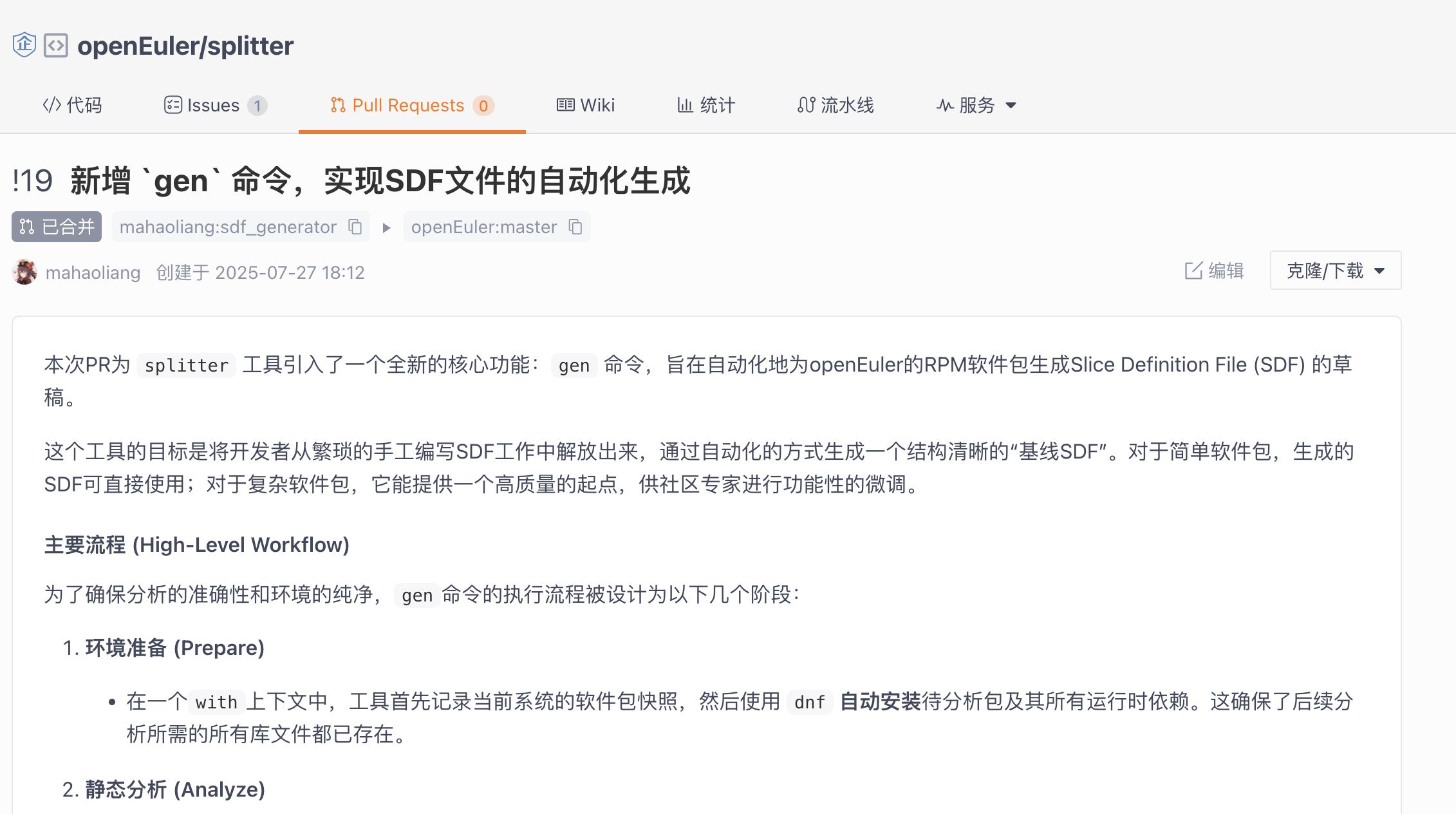
我的任务,就是为splitter开发一个gen命令,实现 SDF 文件的自动化生成。
SDF 生成器的核心实现
我的任务是自动化生成 SDF 文件,但在开始之前,我们首先要理解:SDF 文件究竟是什么?
SDF 文件的构成
一个 SDF(Slice Definition File)文件,本质上是一个 YAML 格式的“软件包拆分说明书”。它精确地定义了一个 RPM 包如何被拆解成多个功能独立的、可按需组合的“Slice”。一个典型的 SDF(以brotli.yaml为例)包含两个核心部分:
|
|
slices(切片):这是主体部分,定义了包内每个文件的归属。contents: 列出了这个 Slice 包含的所有文件路径。比如,brotli_libsslice 包含了所有的.so库文件。
deps(依赖):定义了 Slice 之间的依赖关系。deps: 列出了要让当前 Slice 正常工作,需要依赖哪些其他的 Slice。比如,brotli_libsslice 依赖于glibc_libs,因为brotli的库函数调用了glibc的底层功能。
SDF 的自动化生成流程
理解了 SDF 的构成后,我设计了一套自动化的流水线来生成它。整个流程就像一个工厂的生产线,每一步都有明确的输入和输出:

- 下载 (Download): 首先,从 openEuler 的仓库中下载指定的目标 RPM 包。
- 解压 (Extract): 将 RPM 包解压到一个临时目录,暴露出其内部的所有文件。
- 文件分类 (Classify Files): 遍历所有文件,根据一系列规则,将它们分配到不同的 Slice 中。这是填充 SDF 中
slices和contents部分的核心步骤。 - 依赖分析 (Analyze Dependencies): 对分类好的 Slice(特别是包含二进制文件和库的)进行分析,找出它们之间的依赖关系。这是填充 SDF 中
deps部分的核心步骤。 - 生成 SDF (Generate): 最后,将分类和依赖分析的结果,按照 SDF 的 YAML 格式,写入到最终的文件中。
在这条流水线中,最核心、最具技术挑战性的,无疑是“文件分类”和“依赖分析”这两个环节。
文件分类原理
文件分类就是确定 RPM 包里的每一个文件,应该属于哪个 Slice。
一个软件包通常包含可执行文件、库文件、配置文件、版权声明等。我实现了一个基于规则的智能分类器,它的工作思路是:
-
建立规则:我分析了大量手工编写的 SDF,总结出了一套通用的分类“约定”。例如:
- 以
/etc/开头的文件 -> 归入_configslice。 - 以
/usr/bin/或/usr/sbin/开头的文件 -> 归入_binsslice。 - 以
/usr/lib*/开头且包含.so的文件 -> 归入_libsslice。 - 包含
LICENSE,COPYING等字样的文件 -> 归入_copyrightslice。
- 以
-
精确识别:仅靠路径还不够。比如,在
/usr/bin目录下,既有真正的二进制可执行文件,也可能混杂着 Shell 脚本或 Bash 内建命令的占位符。为了精确区分,我的分类器会调用 Linux 的file命令对每个文件进行“身份鉴定”。只有file命令确认是“ELF executable”的文件,才会被归入_binsslice,从而保证了分类的准确性。
通过这个分类器,我们就能自动地将一个 RPM 包内的上百个文件,有条不紊地分配到不同的slices中。
Slice 依赖分析原理
依赖分析就是找出每个 Slice(尤其是_bins和_libs)依赖了哪些外部的 Slice。
这是技术上最关键的一步。一个二进制文件运行时,需要操作系统动态链接器加载它所依赖的共享库(.so文件),我需要自动追溯这条“依赖链”。
我的依赖分析器采用了一个三步走的策略,来模拟动态链接器的行为:
-
静态解析“需求”:对于
_bins和_libs中的每个 ELF 文件,我使用readelf -d命令。这是一个静态分析工具,它能安全地读取文件头,并列出这个文件在运行时“需要 (NEEDED)”哪些共享库。例如,readelf会告诉我们brotli的库需要libc.so.6。 -
全系统“寻址”:知道了需要
libc.so.6,下一步就是要在系统中找到它。我通过查询ldconfig -p维护的系统库缓存,可以快速地将一个库名(libc.so.6)映射到它在文件系统上的绝对路径(例如/usr/lib64/libc.so.6)。 -
反向“溯源”:拿到了库文件的绝对路径,最后一步就是确定它的“主人”。我使用
rpm -qf <文件路径>命令,它可以精确地反向查询出这个文件是由哪个 RPM 包提供的。例如,rpm -qf /usr/lib64/libc.so.6会返回glibc。
至此,完整的依赖链就建立起来了:brotli_libs -> (需要libc.so.6) -> (位于/usr/lib64/libc.so.6) -> (属于glibc包) -> (因此依赖glibc_libs)。
通过自动化这个流程,我的工具就能为每个 Slice 精确地填充出它的deps列表。
无法逾越的环境依赖
当我完成了上述完整的自动化流水线,并满怀信心地在一个最小化的 openEuler 环境上进行测试时,我遇到了第一个真正的挑战。
我的依赖分析器在第 2 步“全系统寻址”时失败了!原因很简单:我测试用的这个最小化系统里,根本就没有预装待分析包所需要的所有依赖库。
这个问题是致命的。它意味着我的工具能否成功运行,完全取决于它所在的宿主环境是否“恰好”是完备的。这对于一个追求自动化和可靠性的工具来说,是不可接受的。
引入 Docker“沙箱化”分析
在 PR review 的过程中,华为鲁卫军老师建议我使用 chroot 或容器技术来隔离分析环境,避免安装待分析的 RPM 包污染宿主机环境。基于这个建议,我采用 Docker 实现了环境隔离,新的流程是这样的:
-
构建基础镜像:编写了一个
Dockerfile,它会预先构建一个包含了splitter工具本身,以及所有依赖(如python-dnf,binutils等)的“SDF 生成器基础镜像”。 -
隔离的分析流程: 当运行
gen-sdf-docker.sh时:- 它会自动使用上述的基础镜像启动一个干净、一次性的 Docker 容器。
- 在容器内部,它只执行必要的操作:dnf install 来安装待分析包及其运行时依赖。
- 然后调用 splitter gen 命令执行核心的分析逻辑。
-
分析结束后,容器会被自动销毁,对用户的宿主系统环境无影响。
意外的惊喜:第一个成功合并的 PR 竟是“副产品”!
为了实现上述的 Docker 化流程,我需要一个包含了splitter工具本身的基础镜像。这时,鲁老师又给了我一个的建议:
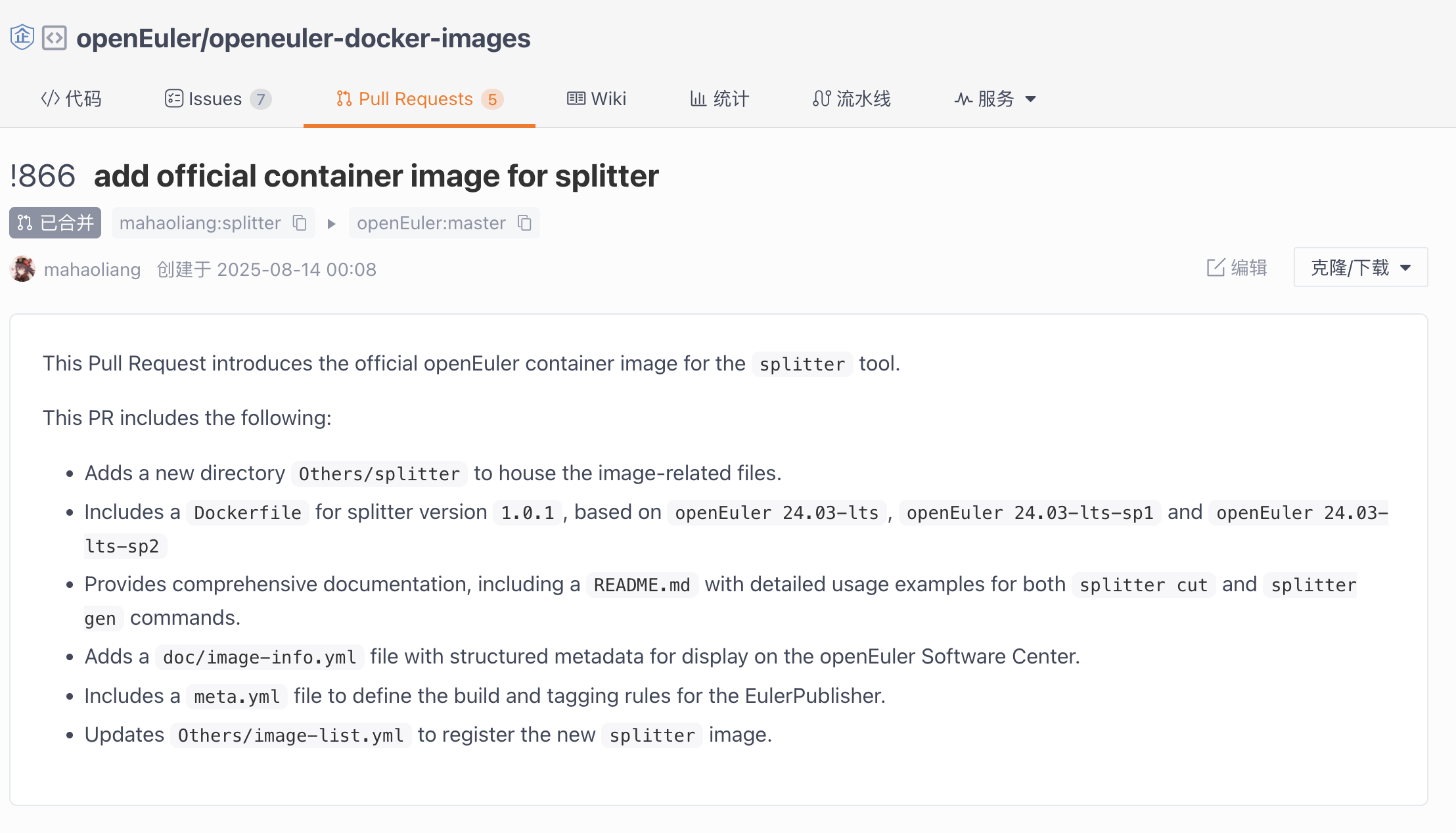
构建 splitter 的 Dockerfile 可以提交到 openEuler 的官方镜像仓库去 https://gitee.com/openeuler/openeuler-docker-images
这让我意识到,这个为了我自己的工具而制作的镜像,本身就可以成为一个交付给社区的“官方应用镜像”!于是,我仔细阅读了官方镜像的贡献指南,编写了Dockerfile和相关的元数据,并提交了PR 到 openeuler-docker-images 仓库。
没想到,这个作为我主线任务“副产品”的 PR,竟然先一步通过了审核,正式合并!那一刻的喜悦难以言表。我的第一个被大型开源项目合并的 PR,就这样诞生了!
主线达成:为华为基础软件贡献代码!
有了官方镜像的加持,我为 splitter 增加 gen 命令的PR也很快被顺利合并了,这标志着我的开源之夏项目取得了阶段性的成功。
这次的感觉又有所不同。虽然我自己在 GitHub 上也发布过一些个人项目,但为 openEuler/splitter 这样重量级的基础软件贡献核心代码,意义完全不一样。它服务于整个 openEuler 的云原生生态,背后是华为和众多社区开发者的努力。能够成为其中一员,哪怕只是贡献了一小部分,也让我感到无比自豪。
后续工作
开源贡献不是一次性的,而是一个持续迭代的过程。在核心功能合并后,我立刻投入到了后续的优化工作中:
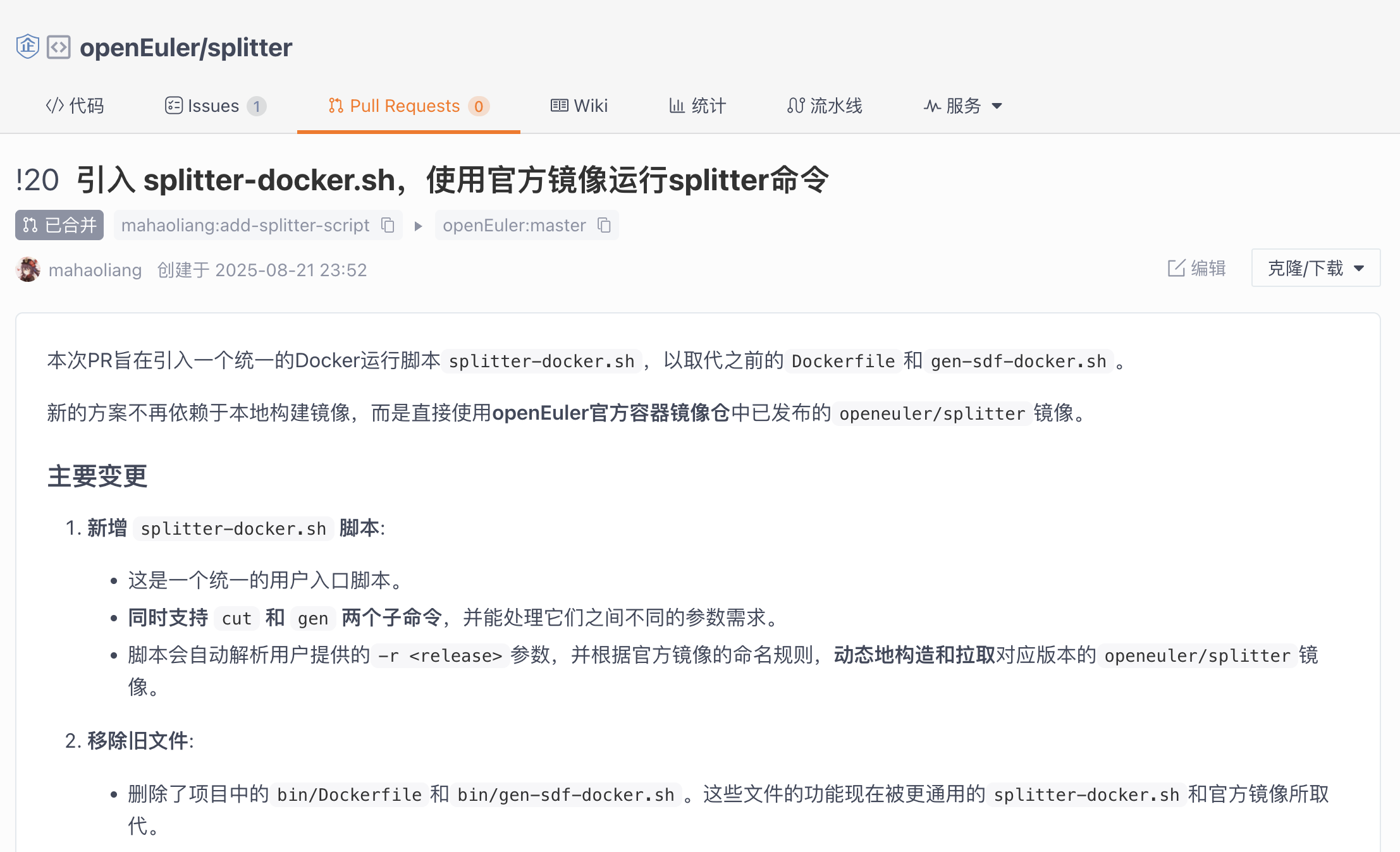
- 提供便携的工具入口:我提交了新的 PR #20,为项目增加了一个
splitter-docker.sh脚本。它封装了所有 Docker 操作,让任何用户都可以通过一条简单的命令,使用官方镜像来运行splitter的cut和gen命令,极大地降低了使用门槛。
在写文章的过程中,这个 PR 也审核通过,成功合并了!
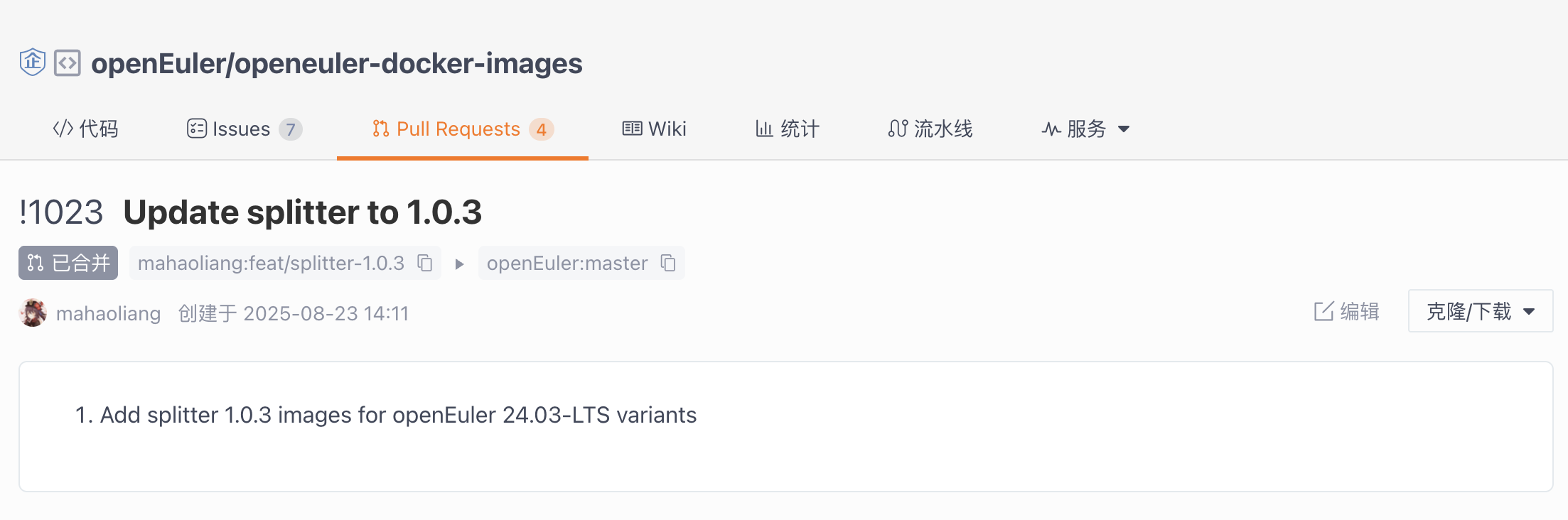
- 更新官方镜像:随着
splitter的版本迭代(比如gen命令的加入),官方镜像也需要更新。我提交了新的 PR #1023来将镜像中的splitter版本升级到最新。
文章还没发布,这个 PR 也审核通过,成功合并了!
这让我深刻体会到,一个功能的完成,往往是另一个优化的开始。
结语
这次开源之夏的经历,让我从一个开源的旁观者,变成了一个真正的参与者和贡献者。我不仅学到了如何设计和实现一个健壮的工具,更学会了如何在社区中沟通、协作,以及如何遵循大型项目的规范和流程。
感谢开源之夏提供了这么好的平台,感谢 openEuler 社区的开放和包容,更要感谢我的导师鲁卫军老师的一路悉心指导。这段旅程才刚刚开始,未来,我希望能为开源世界贡献更多力量。